


鱼群体态特征(体长、体宽)及其与体质量的关系是一种重要的生物差异指标[6-7],也是鱼类研究者们进行生长状态判断以及生态系统建模的重要依据[8-9],还对鱼群生长状态及生物量的判断有较大的帮助[6]。在关于鱼群体态特征(体长、体宽)与体质量关系研究中,相关性系数R2常常被用来验证模型性能,如Sepa P等[10]研究了在厄瓜多尔海洋水域的4种深海软骨鱼的体长、体质量关系,使用幂指数模型(
随着中国深远海养殖事业的发展,大量企业开始着力构建新型养殖模式[15],与此同时大量适养于深海的鱼类开始出现在公众视野[16]。高体鰤(Seriola dumerili)又名章红鱼,是一种生活在水深20~70 m的海洋鱼类,具有较高的食用价值,并且生长速度快、养殖周期短,是一种名贵的经济鱼类[17]。中国从1991年开始高体鰤养殖技术的研究[18],至今对高体鰤的人工养殖技术研究仍未停止[19-20]。2022年6月,南方海洋科学与工程实验室为验证工船养殖高体鰤的可行性,开展了高体鰤养殖实验。为降低养殖过程的饲料成本,需构建一种适用于工船养殖的精准投喂模型,而平均体质量是搭建精准投喂模型的关键要素。通过图像视频数据判断鱼体质量,可以大大地降低鱼群平均体质量获取难度,然而视频图像仅可获悉鱼群体态特征,因此搭建基于鱼群体态特征的鱼体质量预测模型十分必要。使用传统数学模型或神经网络模型搭建体态特征与体质量关系模型时,其对数据集体量要求较高[21]。因此,本研究采用有别于传统神经网络的LSSA-XGBOOST优化树模型完成体质量预测,在保留了决策提升树(XGBOOST)算法处理小样本数据的优良性能前提下,优化了模型结构,使LSSA-XGBOOST模型在仅有少量样本数据的情况下拥有更高的拟合精度,为搭建精准投喂模型提供重要的支撑。
1 材料与方法
1.1 实验材料
2022年6月22日,第一批高体鰤苗放入养殖仓,初始平均体质量为90 g。2022年8月25日,养殖周期为64 d,共取314条高体鰤,测量其体长、体宽和体质量数据。在数据采集过程中,分别使用直尺和电子秤进行样本鱼的体长、体宽和体质量测量,并使用棉手套擦去鱼表面水分,长度精确到1 mm,体质量精确到1 g。
实验地点为广西北海市银海区福成镇西村至营盘南部海域的广西精工深水网箱养殖区。实验平台为中国船舶集团广西公司负责改装修理的“银渔养0039”游弋式实验船(图1),该船总长48.3 m,型宽9.5 m,型深2.9 m,设计吃水1.4 m,并配备双机双桨。养殖实验期间,实验船始终沿养殖区固定航线游弋,从而保证实验期间循环水系统始终能够从外界获取优质海水。
图1

为保证养殖舱内水体质量,舱内四角分别设有进水口,进水流量由舱底电磁流量阀操控,并配备全套水质检测传感器。舱底中心位置为出水口,进出水时可将杂质、死鱼、残饵等养殖废料汇集,再利用出水口涡流的带动排出舱外。
1.2 数据处理
1.2.1 极端学生化偏差(Extreme studentized deviate,ESD)数据降噪方法
在实际水质监测工作中,通常有多个异常数据点,ESD方法将单个异常数据检测 (Grubbs test) 方法扩展,使其能进行多个异常值检测,为了将Grubbs’ test扩展到k个异常值检测,需要在数据集中逐步删除与均值偏离最大的值(最大值或最小值),同步更新对应的t分布临界值,检验原假设是否成立。算法流程如下:
计算与均值偏离最远的残差Rj:
式(1)中:
计算临界值λj:
式(2)中:n为数据量;j为预去除的第j个量;tp,n-j-1表示t分布临界值。
1.2.2 传统数学模型
1)Gauss曲线
Gauss曲线是一种常用的拟合曲线模型,满足正态分布的高斯函数如下:
式(3)中:μ为数学期望;σ2为标准方差。常见应用数学模型拟合鱼类体质量与体态特征关系时,大多选择体长和体质量两项参数。
2)Logistic曲线
Logistic曲线是一种典型的S型函数,又名Sigmoid函数,常常被用来描述生物量增长状态,生物数量增长本身应当符合指数型增长,受环境阻力(生存空间、天敌数量等)的影响,在其增长至一定数量后,达到极限数量K值并维持稳定。从整体曲线变化来看,前期爆炸增长及后期环境阻力减缓其增长,使曲线整体呈S型,即增长速率先增大后减小。其数学方程表示为:
式(4)中:P0为初始状态;K为终值;参数r用于衡量变化速度。
3)幂函数曲线
幂函数曲线即指数函数,属于初等函数之一,常用于描述微生物增长状态,即拥有所有生长所需资源且无环境阻力下的生物量增长形式。方程结构调整如下:
式(5)中:K、t为常数;
目前常用的体长、体质量关系拟合方法为Von Bertalanffy方程[24]:
式(6)中:W表示体质量;L表示体长;a、b均为实数,可使用SPSS软件计算得出。
1.2.3 LSSA-XGBOOST拟合模型
1)麻雀搜索算法(Sparrow search algorithm,SSA)及其改进
麻雀搜索算法是东华大学的薛建凯[25]于2020年提出的一种新型群智能寻优算法,在鸟群觅食过程中,优先找寻到食物的个体称之为发现者,发现者会向其他个体即加入者传递信息,而加入者与发现者相互竞争、抢夺资源。麻雀算法按此模式多次群体寻优,最终选出获得最高适应度个体,即算法得出的最优解。
初始化种群个体可表示为:
式(7)中:d表示待优化参数量;n为种群数量。
种群适应度为F(X),形式为个体适应度
发现者位置随搜寻范围变化不断更新,公式如下:
式(9)中:p为迭代次数;i、j分别表示个体与种群数(Xi,j表示第i个种群第j个个体);pmax表示最大迭代次数;α为(0,1]区间内的随机数;R2表示预警值,范围取[0,1];ST表示安全值;范围取[0.5,1.0];Q为随机数;L为维度1×d的全1矩阵。
加入者通过观察发现者位置,并随之完成位置更新:
式(10)中:XP是目前发现者所占据的最优位置;Xworst为全局最差位置;A表示所有值随机为1或-1的1×d矩阵;
警觉者初始位置在群体中随机产生,其位置表示为:
式(11)中:Xbest是当前的全局最优解;β为步长控制系数,其特征服从(0,1)间的正态分布;K是区间[-1,1]下的随机数;fi表示当前个体适应度;fg表示最佳适应度;fw为最差适应度;ε为常数。
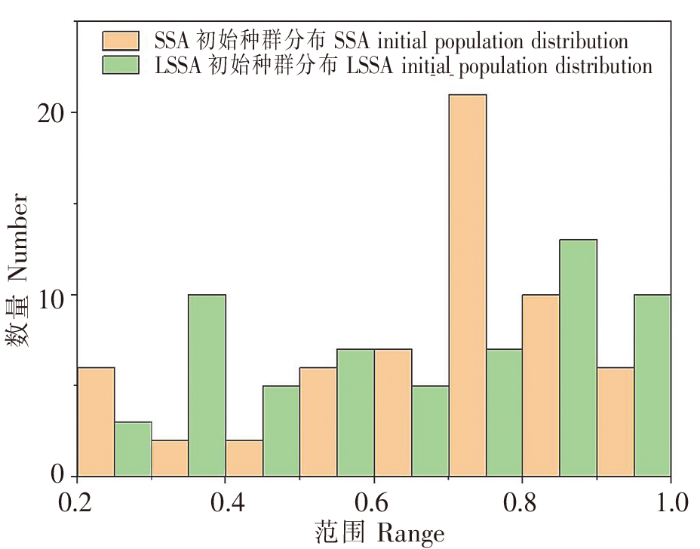
(1)混沌优化(LSSA)
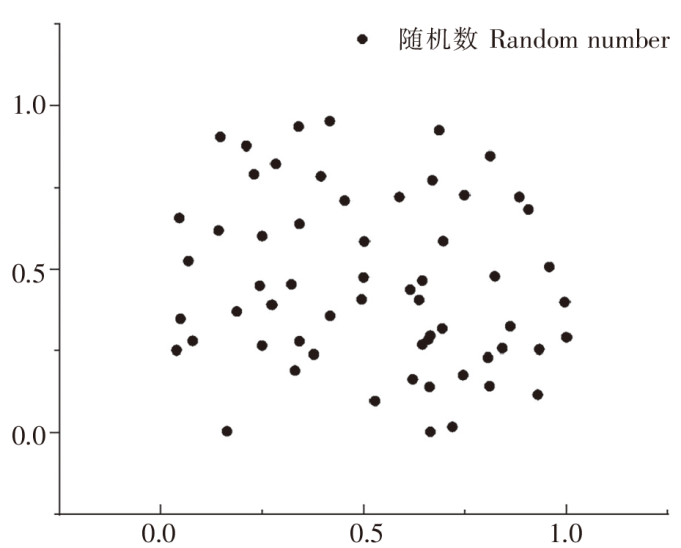
麻雀算法(SSA)初始种群产生方法为构成种群数量(pop)×目标参数(dim)的均匀分布的随机矩阵,这种方法在群体检索过程中会生成均匀分布在一片区域内的点,如图2所示。
图2
(2)混沌随机矩阵优化
麻雀算法初始种群优化方法有多种方式,实验所用混沌随机数发生器基于Logistic方程,其表现形式为:
式(12)中:参数u≥3.569 946后,X的值不再发生震荡,随后进入混沌状态。
混沌SSA基于该原理随机产生的随机值分布更加分散,如图3所示。
图3
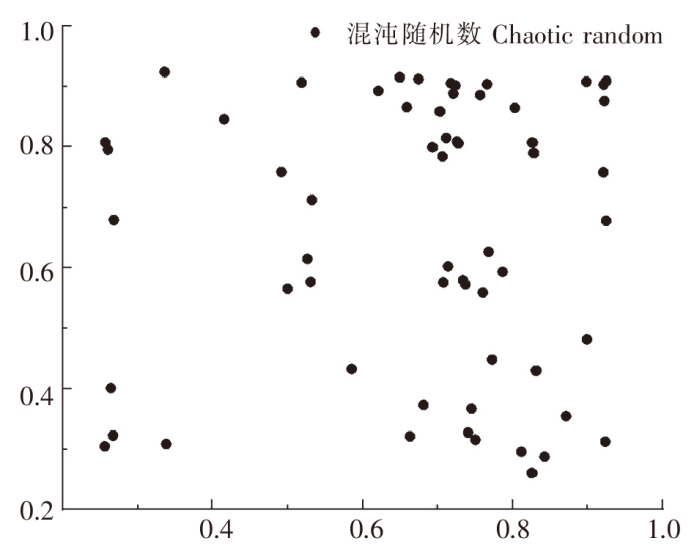
图4
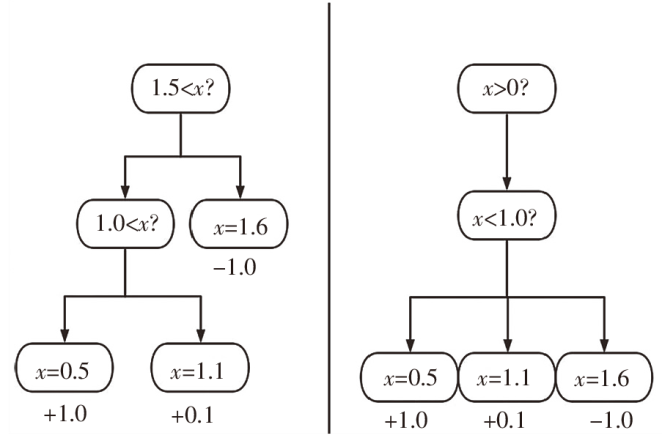
2)XGBOOST极端梯度提升树
XGBOOST算法于2014年由Chen T Q等[27]提出,其算法核心在于将多个低准确率分类器组合成一个高准确率模型,针对问题,将对象进行不断分类判断并打分,最终某个对象的分数是所有XGBOOST树评分之和。XGBOOST算法在处理分类和回归问题中均具有十分良好的表现。
对于XGBOOST而言,其输出F是由多个评分树结果相加,表示方法如下:
式(13)中:
式(14)中:
图5
在实际运算中,很多关系无法通过简单累加公式拟合得出,为提高提升树的渐进能力,方程增加了二次项函数,简化后的正则公式为:
式(15)中:
树结构搭建完成后,需对其结构质量进行评估,公式为:
式(16)中:q为待评估的结构;hi、gi及Ij分别表示损失函数二阶、一阶统计量、叶节点实例集。
模型在正常运算时,由于叶节点繁多、结构的评估验证是一层一层循序推进的,单层若有左右两个节点(表示为IL和IR),那么该层的损失函数计算将以下列公式表示:
式(17)中:I表示左右两个实例集IL、IR的并集。
3)LSSA优化XGBOOST模型
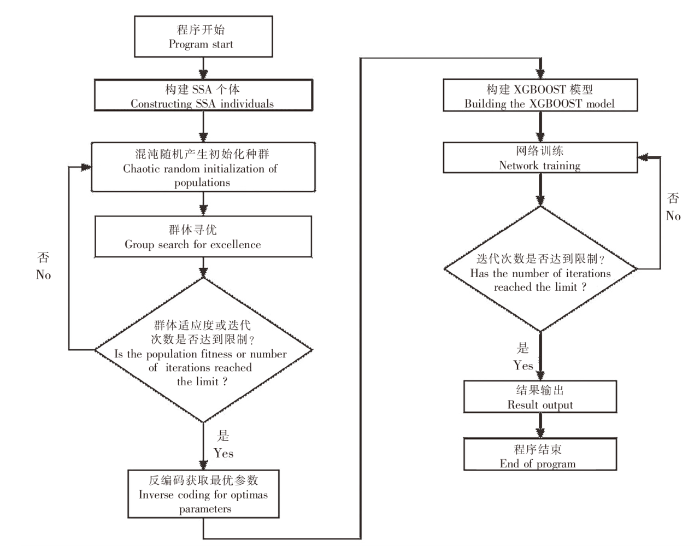
使用决策提升树(XGBOOST)模型进行高体鰤体态和体质量的预测是一个不断调整树模型各节点权值的过程,旨在使树模型函数持续逼近体态和体质量之间的关系。类似于常规的有监督学习,XGBOOST模型的预测过程需要根据训练集(体长和体宽数据)预测目标变量(体质量数据)。由于模型无法一次性预测成功,因此每次预测结束后,XGBOOST模型会新增一棵决策树,根据误差函数对前一棵树的预测结果进行调整和纠正,直至最终预测结果达到精度要求。传统XGBOOST模型最佳树深度、最佳学习率以及最佳迭代次数等3项超参数由用户随机定义,导致模型效果无法保证。为提高XGBOOST拟合精度,使用混沌SSA算法对其3个主要参数进行寻优,获取最佳树深度、最佳学习率以及最佳迭代次数(图6)。
图6
2 模型拟合结果
2.1 ESD数据降噪结果
图7
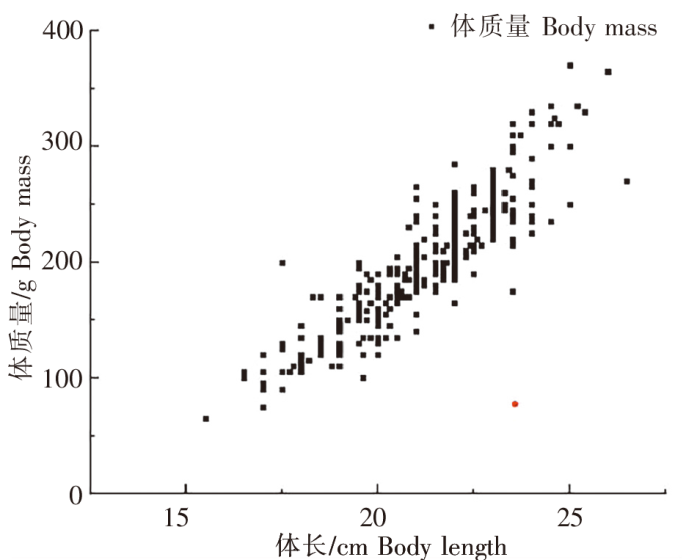
图7
体长、体质量关系散点图(ESD剔除)
注:红色点为剔除数据。
Fig.7
Scatter diagram of body length and body mass (ESD-excluded)
Notes:The red dot represented excluded data.The same as in
图8
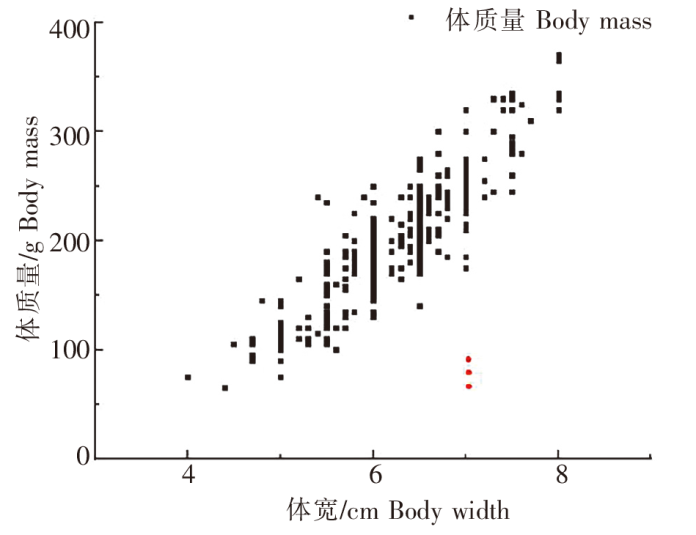
图8
体宽、体质量关系散点图(ESD剔除)
Fig.8
Scatter diagram of body width and body mass(ESD-excluded)
2.2 数学模型拟合结果
2.2.1 常规数学模型拟合结果
1)Gauss曲线
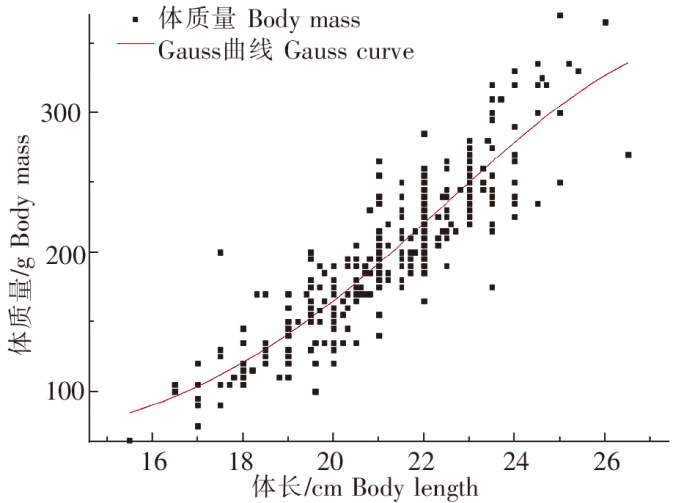
使用Gauss曲线拟合高体鰤体长-体质量关系,拟合效果见图9,整体数据集呈正相关趋势,数据点均匀分布在曲线两侧,曲线终点尚未达到峰值,未呈现完整的山峰形Gauss曲线。
图9
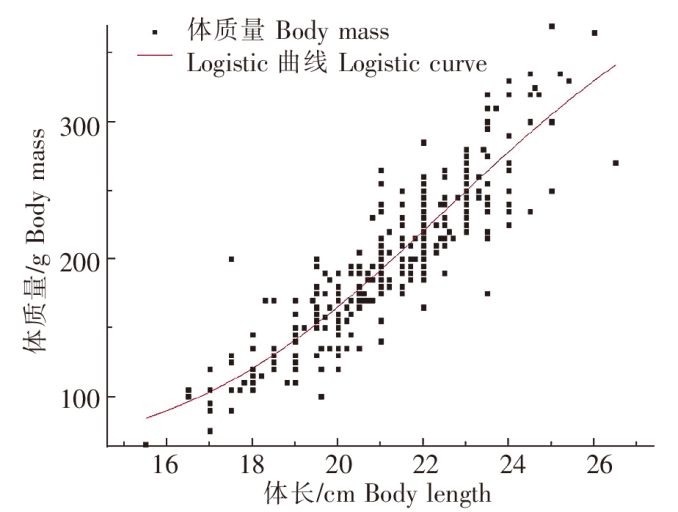
2)Logistic曲线
使用Logistic曲线进行高体鰤的体长、体质量关系拟合,拟合效果见图10,整体增长较为平稳,增长速率变化不大,未呈现较为明显的S型曲线。
图10
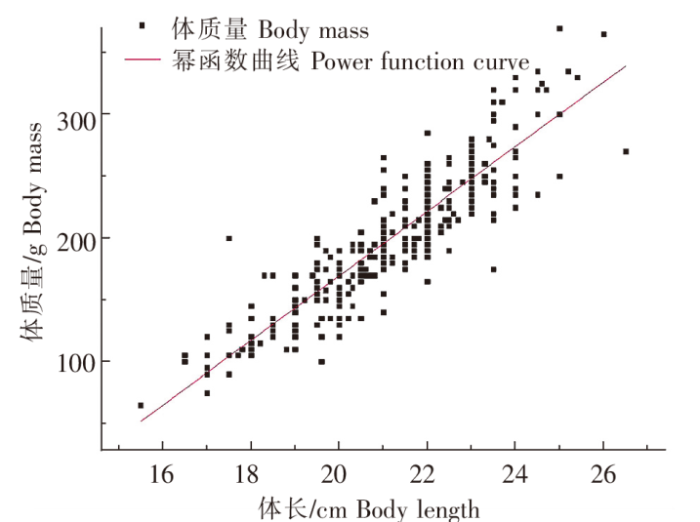
3)幂函数曲线
利用幂函数,选择体长和体质量两项因素完成高体鰤体态特征与体质量关系的拟合,拟合曲线见图11。
图11
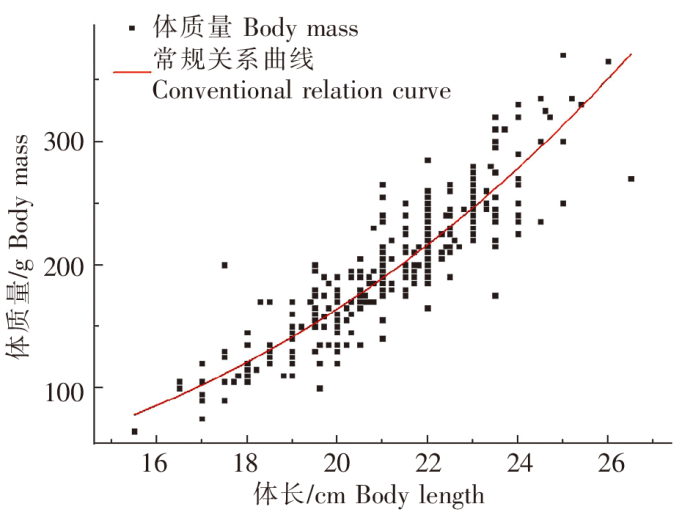
4)Von Bertalanffy方程
Von Bertalanffy方程拟合效果如图12所示。体长、体质量的关系式为
图12
2.2.2 LSSA-XGBOOST模型拟合结果
开始实验后,将XGBOOST的3项参数作为待优化量输入SSA模型,SSA模型参数设置如下:
fun=@getObjValue;%目标函数
dim=3;%优化参数个数
lb=[0.001,0.001,0.01];
% 优化参数目标下限(最大迭代次数,深度,学习率)
ub=[100,20,1];
% 优化参数目标上限(最大迭代次数,深度,学习率)
pop=60;%麻雀数量
Max_iteration=10;%最大迭代次数
params.objective='reg:linear';
% 回归函数
种群初始化参数设置如下:
Pop=60;%种群规模
Dim=3;%优化参数个数
Seed=0.5;%起始位置
U=3.8;
%u混沌序列参数,u取[3.569 9,4]
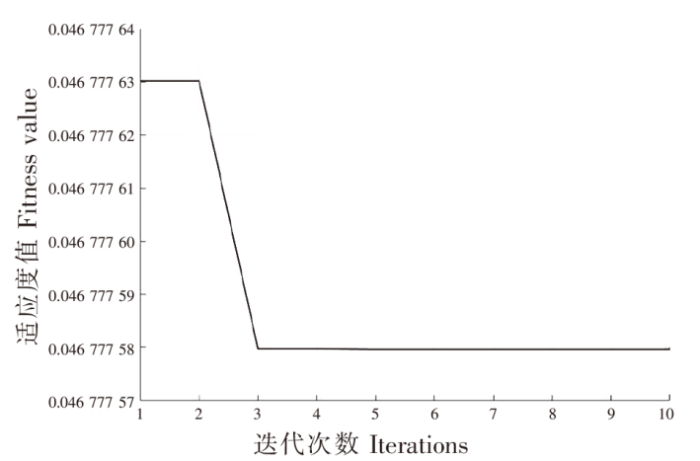
SSA群体适应度随迭代次数变化曲线如图13所示,从第三代开始,群体适应不再下降,即种群已达到最佳适应度。
图13
此次实验以体长、体宽两项参数为输入值预测体质量,这是由于在实验过程中发现使用体长或体宽单一参数输入预测体质量时,LSSA-XGBOOST模型拟合度分别为0.795 56和0.824 06,仅略高于部分数学模型,而使用双参数输入时拟合度有较大提升,拟合度R2达到0.944 16。预测值与真实值的拟合效果对比见图14,在100个样本点的拟合跟踪中表现良好,仅丢失少量目标点。
图14
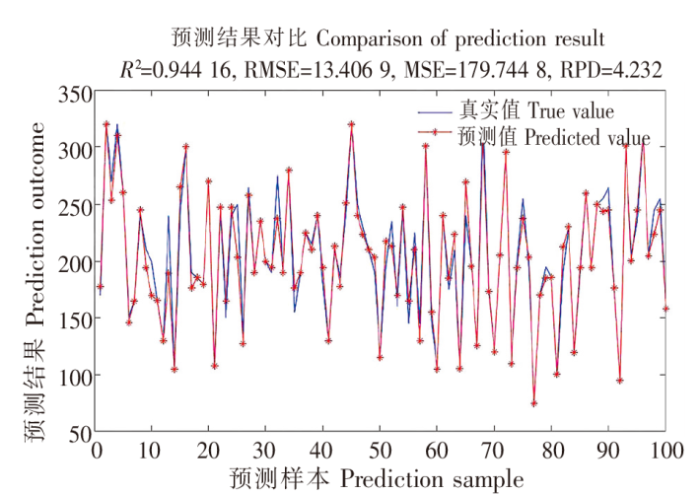
图14
预测值与真实值对比图
注:RMSE为均方根误差;MSE为均方误差;RPD为相对百分比差异。
Fig.14
Comparison between predicted value and real value
Notes:RMSE is root mean square error;MSE is mean square error;RPD is the relative percentage difference.
3 分析与讨论
3.1 与神经网络模型的对比分析
由上述数学模型拟合效果可知,针对此次高体鰤养殖实验测量数据的常规数学模型拟合并非最优方法。神经网络模型属于自适应非线性模型,大量数据表明,人工神经网络在处理常见回归拟合问题时有优异表现[28],除传统BP神经网络外,多种优化BP模型如遗传算法优化BP(GA-BP)、粒子群优化BP(PSO-BP)等都具有处理回归拟合问题的能力,这些优化算法大多在BP神经网络初始化时采用寻优算法获取最佳的权值、阈值等初始参数,从而有效提高BP神经网络拟合精度。PSO-BP是较为常见的群体寻优算法,在解决回归预测问题时常常优于GA-BP和传统BP [29]。本文选用传统BP神经网络以及PSO-BP神经网络与LSSA-XGBOOST算法对比,结果如图15所示,传统BP神经网络拟合度R2为0.877 5,粒子群优化BP为0.910 5,而本文所用LSSA-XGBOOST模型相关性系数R2为0.947 9。以图15中第11个点拟合效果为例,BP和PSO-BP神经网络的拟合误差已经接近其最佳误差,而LSSA-XGBOOST每棵树模型的预测都使用shrinkage,削弱其对结果的影响,从而提升整体模型的泛化能力,为后续训练留出更多的学习空间,有效地防止过拟合。此外,常见神经网络算法需要大量数据以支撑其算法模型的深度和训练量,从而提高预测精度,而XGBOOST则不需要太过庞大的数据集,这是由于决策提升树模型在训练过程中遵循确定性原则,而确定性原则使其更容易记住简单的数据变化规律,一旦规律过于复杂,其学习效果便会弱于神经网络模型。
图15
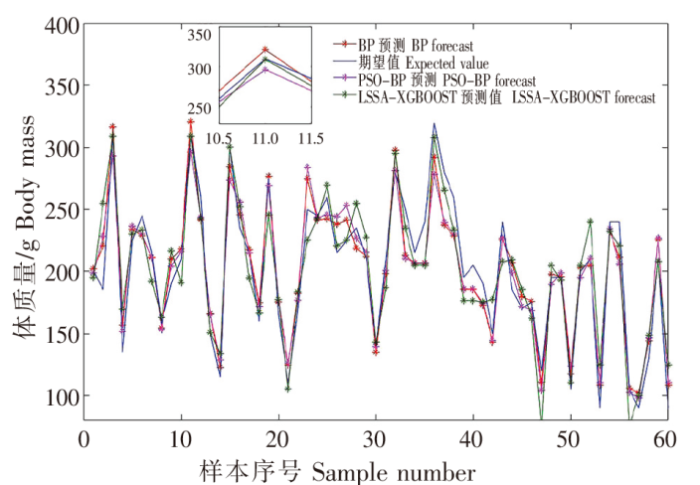
3.2 总体对比
表1 7种拟合模型拟合度R2对比
Tab.1
| 模型 Model | 自变量 Independent variable | 因变量 Dependent variable | 相关性系数 R2 |
|---|---|---|---|
| Gauss | 体长 | 体质量 | 0.822 5 |
| 体宽 | 体质量 | 0.708 5 | |
| Logistic | 体长 | 体质量 | 0.772 5 |
| 体宽 | 体质量 | 0.708 4 | |
| 幂指数 Power-exponent | 体长 | 体质量 | 0.771 9 |
| 体宽 | 体质量 | 0.709 6 | |
| W=aLb | 体长 | 体质量 | 0.771 0 |
| BP | 体长+体宽 | 体质量 | 0.877 5 |
| PSO-BP | 体长+体宽 | 体质量 | 0.910 5 |
| LSSA-XGBOOST | 体长+体宽 | 体质量 | 0.947 9 |
表2 LSSA-XGBOOST模型与神经网络算法各项误差对比
Tab.2
| 模型 Model | 平均绝对误差 MAE | 均方误差 MSE | 均方根误差 RMSE |
|---|---|---|---|
| BP | 13.988 | 300.165 5 | 17.325 3 |
| PSO-BP | 13.716 | 243.015 2 | 16.412 4 |
| LSSA-XGBOOST | 9.042 | 203.533 0 | 14.266 5 |
4 结论
1)本文提出的LSSA-XGBOOST模型以决策提升树模型(XGBOOST)为基础进行改进,最终使得LSSA-XGBOOST模型在小样本数据集下有优于其他传统及改进神经网络的表现。
2)与常规数学模型拟合相比,LSSA-XGBOOST模型拟合度相关性系数R2(0.947 9)提高了约10%;与传统BP神经网络和PSO-BP相比,LSSA-XGBOOST模型相关性系数R2提升约3%,且MAE、MSE和RMSE三项误差都有明显降低。在处理小样本数据集的回归拟合工作时,LSSA-XGBOOST模型优于传统数学模型和常规神经网络模型,能为工船养殖高体鰤精准投喂提供理论依据,后续建议在养殖过程中扩充样本数据集,并提高混沌随机数发生器性能,将有效提高高体鰤体质量的预测精度,为饲料投喂、成鱼出仓时机判断及市场预估提供参考。
参考文献
基于自适应模糊神经网络的鱼类投喂预测方法研究
[J].
在集约化水产养殖中,鱼类的投喂水平直接关系到养殖效率和生产成本。针对当前水产养殖中存在的投喂量不合理、饲料浪费严重的问题,以实现投喂量的精准预测为目的,提出了一种基于自适应模糊神经网络的鱼类投喂量预测方法。该方法以罗非鱼为研究对象,选择水温和鱼的平均体重2个因素作为输入变量,利用混合学习方法,通过训练和学习获得最优模糊规则库,基于自适应神经网络模糊推理系统(adaptive network fuzzy inference system,ANFIS)建立投喂量预测模型,取得了较好的预测效果。基于ANFIS的投喂量预测模型的均方根误差、平均绝对误差和平均绝对百分比误差分别为1.18、0.74和0003 1,均远远小于原始模糊推理投喂量预测模型的指标值,其网络预测能力优于原始模糊推理预测模型。因此,该模型不仅可以在无监督条件下对鱼进行科学投喂,节省人力成本,而且能为合理的投喂提供技术支撑和理论支持。
Length-weight relationships for eight Chondrichthyes from the north-eastern Atlantic Ocean
[J].
Temporal variation in length-weight relationship,growth and condition factor of Acentrogobius viridipunctatus in the Mekong Delta,Viet Nam
[J].
Data on length-weight and length-length relationships,mean condition factor,and gonadosomatic index of Rutilus rutilus and Perca fluviatilis
[J].
Length-weight relationships of wild penaeid shrimps in Malindi-Ungwana Bay:implications to aquaculture development in Kenya
[J].
Length-weight relationship of four deep-sea chondrichthyans (Elasmobranchii & Holocephali) in Ecuadorian oceanic waters
[J].
Length-weight relationships of three species of pelagic sharks from southeastern Arabian Sea
[J].
高体鰤人工繁殖、育苗及养殖技术的研究
[C]//
XGBoost:a scalable tree boosting system
[EB/OL].[

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}